
Cross-modal Learning for Event-based Semantic Segmentation via Attention Soft Alignment
Published:
Abstract
By demonstrating robustness in scenarios characterized by high-speed motion and extreme lighting changes, event cameras hold great potential for enhancing the perception reliability of autonomous driving systems. Because of its novelty and data sparsity, the progress of event-based algorithms is hindered by the scarcity of high-quality labeled datasets. In this work, we propose CMESS (Cross-Modal learning for Event-based Semantic Segmentation), which eliminates the need for event labels by transferring the model from labeled image datasets (source domain) to unlabeled event datasets (target domain) via unsupervised domain adaptation (UDA). Compared to existing UDA methods that require hard alignment of visually consistent embeddings, our approach achieves soft alignment via cross-attention and then augments it with knowledge distillation to convey fine-grained source knowledge to the target domain. Additionally, we introduce an event-driven bidirectional self-labeling method to generate weakly supervised signals for event-only datasets. These designs facilitate cross-modal learning without requiring per-pixel paired frames or online reconstruction. Experimental results show that our method outperforms existing state-of-the-art methods in both UDA and supervised settings on common evaluation benchmarks, making it a universal framework for further unlabeled event-related visual tasks.
Framework
The overview of CMESS is presented in above figure, which comprises three stages: Source-Path Initialization (SPI), Target-Path Labeling (TPL), and Cross-modal Learning (CML). During training, our method undergoes three-stage to transfer a task from the image to the event domain. Stage 1, SPI, initializes source model M_S and synthetic target model M_T’ from the labeled image dataset, where M_S is trained directly using labeled images through supervised learning. In stage 2, TPL, independent inference on the unlabeled event dataset and merging their predictions to generate event pseudo-labels for self-supervised signals. Stage 3, CML, takes pseudo-pairs from the image (synthetic events) and event (real event) domains as input, then achieves attention soft alignment within the weigh-sharing triple-branch transformer, and further incorporates knowledge distillation to transfer similar image knowledge to the event domain. During inference, only the target branch is required, without extra computational overhead.
Visualization Results
Qualitative samples on the DDD17 dataset in the UDA setting. Compared to VID2E and ESS, our method is more accurate in predicting the details.

Qualitative results on the DDD17 dataset in the supervised setting. The DDD17 annotations have limitations in terms of accuracy, but our method accurately distinguishes very small persons and objects.

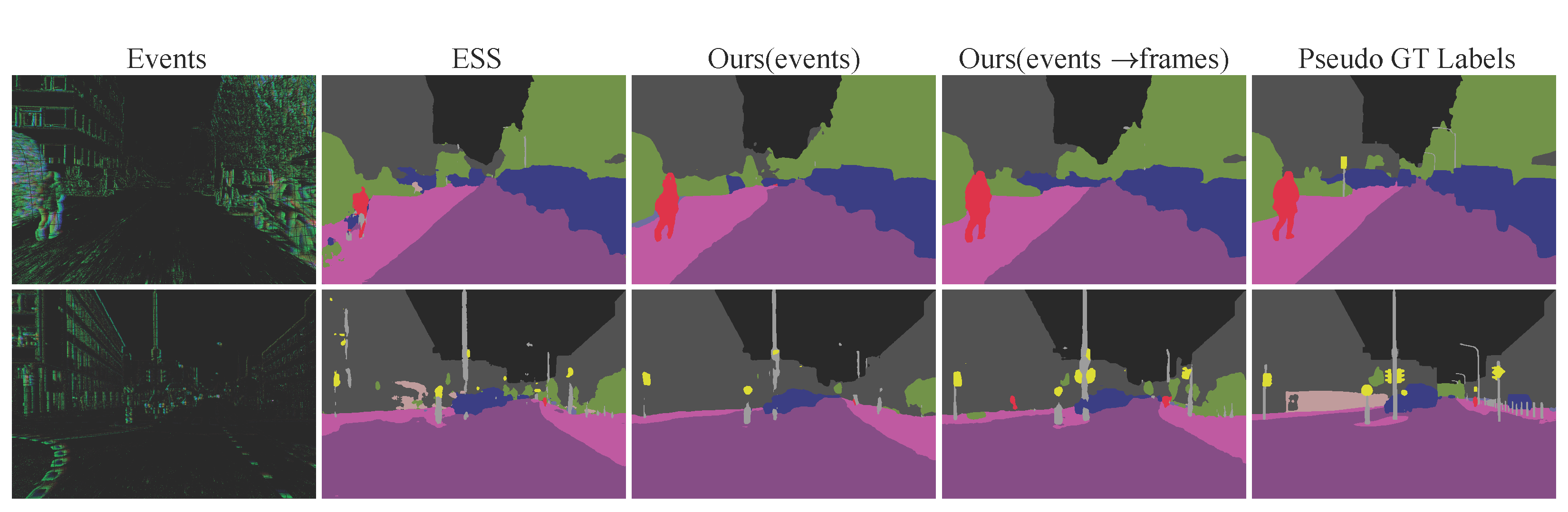
Qualitative samples on DSEC-Semantic in the UDA setting. Our method utilizes cross-attention to suppress the noise during alignment, leading to more precise segmentation results.

Qualitative results on the DSEC-Semantic dataset in the supervised setting.
The comparison of frame and event segmentation in overexposed scene (HDR).

The heatmap of the cross-attention weights for a sample of pseudo pairs. As visualized in the figure, patches in the pseudo pairs with similar human semantic categories achieve higher weight distribution, which confirms the effectiveness of cross-attention.

Performance analysis
We have conducted a performance analysis of CMESS [1] and ESS [2] in terms of training hours and model parameters. Based on the DSEC-Semantic dataset, we experimented on a single 32GB Tesla V100 GPU, with a batch size of 8 and epochs of 100, the results are shown in the following table:

ESS follows a two-stage training process. Firstly, it initializes an image encoder in the image domain. Due to time constraints, we did not repeat this step, leaving the training hours for Stage 1 unknown. Subsequently, in Stage 2, ESS trains the network in the event domain for the UDA task, taking 148 hours to complete. In contrast, CMESS consists of three stages. In Stage 1 (TPL), it took 10 hours to train M_S and 26 hours to train M_T’. Stage 2 exclusively involves inference on models to generate pseudo-labels without any additional training cost. Moving on to Stage 3 (CML), it required 45 hours to train the weight-sharing triple-branch transformer based on pseudo-pairs, summing up to a total of 71 hours for all training processes. It’s noteworthy that utilizing multiple GPUs for distributed training can significantly enhance training speed. Besides, we measured the model parameters to assess computational requirements. The model parameters for CMESS remain constant at 3.71 × 10^6 due to weight-sharing, while those for ESS are 12.91 × 10^6. CMESS employs the lightweight transformer Segformer-B0 [3] as the backbone, and does not introduce E2VID into online training, so the training hours and parameters are less than ESS.
[1] Chuyun Xie, Wei Gao*, Ren Guo. Cross-modal Learning for Event-based Semantic Segmentation via Attention Soft Alignment. IEEE Robotics and Automation Letters, Submitted.
[2] Sun Z, Messikommer N, Gehrig D, et al. Ess: Learning event-based semantic segmentation from still images[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 341-357.
[3] Xie E, Wang W, Yu Z, et al. SegFormer: Simple and efficient design for semantic segmentation with transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 12077-12090.
Reference
Chuyun Xie, Wei Gao*, Ren Guo. Cross-Modal Learning for Event-Based Semantic Segmentation via Attention Soft Alignment. IEEE Robotics and Automation Letters, vol. 9, no. 3, pp. 2359-2366, March 2024. DOI